在上一篇文章中,我们用python实现了对图片网站上的小姐姐图片爬取:
https://www.xiaoweigod.com/code/1666.html
这篇文章就来演示一下,对爬取下来的小姐姐图片进行颜值判定,然后根据颜值高低来对图片进行排序。
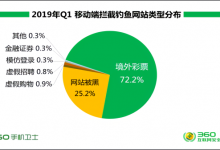
颜值判定的API是百度的,这个API我测试过好多图,准确度还蛮高,且免费不限制使用次数(限速每秒2次),毕竟百度是国内大厂 (~ ̄▽ ̄)~。也希望大家手下留点情,不要把百度人脸识别API和小姐姐图片站给玩坏了
百度人脸识别项目:http://ai.baidu.com/tech/face/detect
环境准备:
python3,requests模块,百度人脸识别API。
python3怎么装我就不说了,requests模块的话,在python环境的电脑里,直接打开cmd,执行pip install requests 就可以了。
人脸识别API:打开http://ai.baidu.com/tech/face/detect 点立即使用,登录账号后创建一个应用,名字随便写:

创建完成后,在“管理应用”里面找到你的APPid,API key,Secret key就可以了。

一、逻辑分析
在正式开始写之前,需要把逻辑给分析清楚,然后根据这个逻辑,来编写相应的代码。在本篇文章的这个程序中,首先要把图片上传到百度云人脸识别服务器中进行识别,然后过滤掉没有人脸的图、男性的图和人脸置信度过低的图,然后再对图片进行颜值排序。
流程如下:
① 遍历本地文件夹中的图片
② 将本地照片上传到百度云的人脸识别服务器中,返回识别参数。
③ 分析返回的参数,过滤掉不是人脸的图片
④分析返回的参数,过滤掉男性的图片
⑤ 分析返回的参数,过滤掉人脸置信度过低的图片
⑥从返回的参数中取出图片的颜值,加上这张图片对应的路径,统一存放到一个字典中,格式为 {路径:颜值}
⑦ 循环取出字典中颜值最大的元素的路径和颜值,删除最大值,复制到新的文件夹,然后重命名文件为 排名+颜值。
二、分析百度人脸识别API
文档参考:http://ai.baidu.com/docs#/Face-Detect-V3/top
根据文档描述,可以看到,需要先使用你的API key和Secret id请求鉴权秘钥,然后再通过鉴权秘钥去请求人脸识别服务器。
1.计算鉴权秘钥(access_token)

运行结果:

这一串东西就是我们需要的鉴权秘钥。
2.发送图片到百度的人脸识别服务器
因为本次程序是识别本地的图片,所以我们不考虑文档中的网络图片和图片face_id的情况。
根据文档,我们需要发送的内容有:access_token(放在url参数里),图片的base64编码和图片的类型,请求的参数:beauty(颜值),gender(性别)。发送方式为 post。我们以识别下面这张图的小姐姐为例:


运行一下,成功返回了:

3.处理返回的数据
上一步中完整的返回数据如下:
{'error_code': 0, 'error_msg': 'SUCCESS', 'log_id': 7594757925058, 'timestamp': 1538733924, 'cached': 0, 'result': {'face_num': 1, 'face_list': [{'face_token': '8cea6b27151c7e5253d501fb14cda5fc', 'location': {'left': 342.3506775, 'top': 111.2269287, 'width': 89, 'height': 84, 'rotation': -16}, 'face_probability': 1, 'angle': {'yaw': 8.847219467, 'pitch': 6.044753075, 'roll': -17.03232384}, 'beauty': 65.53157043, 'gender': {'type': 'female', 'probability': 0.9999910593}}]}}
这是一组字典嵌套列表嵌套字典嵌套字典的数据。我们需要的数据如下:
error_code:判断是否成功识别 【0为成功,其他code为不成功】
result里的face_list里的的第1个元素中的 face_probability 【0-1,越大越可能是人脸】
result里的face_list里的的第1个元素中的 beauty 【0-100,越大颜值越高】
result里的face_list里的的第1个元素中的 gender 中的 type 【性别,male为男性,female为女性】
这些元素的访问方法如下:

运行一下看结果:

这里就获取到了我们需要的信息。
三、完整代码的实现
import requests from json import loads from base64 import b64encode import os import shutilAPI_key = '改成你自己的' Secret_key = '改成你自己的'
根据文档,定义获取access_token的url地址,传入API key和Secret key
token_url = token_url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={api_key}&client_secret={api_sec}'.format(api_key=API_key,api_sec=Secret_key)
请求秘钥,获得返回的文字内容
token_request = requests.get(token_url).text
将返回的内容格式化为字典形式,并访问字典中"access_token"的值
access_token = loads(token_request)['access_token']
写一个函数
def AiFace(img_path):
url = 'https://aip.baidubce.com/rest/2.0/face/v3/detect?access_token=' + access_token #请求的url,加上access_token参数 img = open(img_path,'rb').read() #二进制方式读取图片 img_b64 = b64encode(img) #将图片转为base64编码 #发送的数据 data = { 'image':img_b64, #图片的base64编码 'image_type':'BASE64', #图片类型 'face_field':'beauty,gender', #需要返回的参数 'max_face_num':1 #每张图片中最多返回一张人脸 } r = loads(requests.post(url,data).text) #请求一下,然后把返回的内容转化为字典形式
if r['error_code'] == 0: #如果识别成功,函数结束,return出结果 return r['result']['face_list'][0] #如果不成功,那么啥都不return(None)
开始运行
img_folder = 'd:/test/' #图片文件夹 save_folder = 'd:/result/' #结果保存的文件夹
# for root,path,files in os.walk(img_folder): #遍历图片文件夹 info_dic = {} count = 0 for file in files: complete_path = os.path.join(root,file) #获得文件的完整路径 if '.jpg' in complete_path: #去除不是jpg的文件 count += 1 print(str(count)+'-检测--->'+complete_path) result = AiFace(complete_path) # 实例化函数 if result != None: #去除识别错误的文件(没有人脸) face_probability = result['face_probability'] # 是人脸的可能性 beauty = round(result['beauty'], 2) # 颜值,保留二位小数 gender = result['gender']['type'] # 男女 if face_probability >0.75: #去除人脸置信度小于0.75的图片 if gender == 'female': #去除不是女性的图片 info_dic[complete_path] = beauty #结果保存到字典中 {文件路径:颜值} print('---检测到人脸,颜值'+str(beauty)+'分---')
os.makedirs(save_folder) face_count = len(info_dic) #计算字典长度
for i in range(1,len(info_dic)+1): #遍历字典中的内容 max_beauty_file = max(info_dic,key=info_dic.get) #找到最高颜值对应的key(文件路径) beauty_score = info_dic[max_beauty_file] #找打到最高颜值 img_name = str(i)+'-('+str(beauty_score)+'分).jpg' shutil.copy(max_beauty_file,save_folder+img_name) #复制到新文件夹并改名为排名+颜值分 info_dic.pop(max_beauty_file) #删除字典中的这个元素 i+=1
print('\n完成,共检测'+str(count)+'张图片,其中'+str(face_count)+'张有人脸') print('颜值排序已保存到:'+save_folder)
上面每一步都注释了,这里的颜值排行主要通过字典排序的算法实现。
随便找几张图测试一下:

运行结果:

排序文件夹:

、
















写的真好
哈哈哈哈,颜值排序,你可真是个项目鬼才!